Zalecam ostrożność #1: Stochastyczna papuga, czyli rzecz o czacie GPT.
Pytanie, które nurtuje mnie od lat, brzmi: „Dlaczego tak często mała grupa osób robi taki straszny bałagan, który potem muszą długo sprzątać po nich inni?” Ile było takich przypadków w historii, kiedy ludzie pchani ideami budowy lepszego świata, w imię postępu, dawali sobie prawo do działań, które były i są przyczyną cierpienia tak wielu istot? Wojny, atomowe bomby i oceany pełne śmieci. Czy była to decyzja tych ludzi, czy bardziej splot wyłaniających się w danej chwili i miejscu możliwości, który pchał ich do działania? Rodzi się ciekawy wątek…, jednak dzisiaj zajmę się tematem pilnym i poważnym! Wyłania się bowiem nowy bałagan, który w sposób nieliniowy może zmienić świat, który znamy. Zanim zacznę bić na alarm, aby nie powodować od razu zbyt dużej paniki, zalecę na początek ostrożność.
Wprowadzenie
Od końca listopada 2022 infosfera zalewana jest fragmentami rozmów z ChatemGPT oraz coraz większą ilością deepfake’ów (znanych od kilku ładnych lat) i obrazków wygenerowanych m.in. przez MidJourney, Stable Diffusion czy DALL-E 2. Firmy technologiczne, zarówno te największe, jak i te całkiem małe, wespół z marketingowcami, prześcigają się w wymyślaniu zastosowań i zacierają ręce licząc przyszłe zyski, przy akompaniamencie mediów i technologicznych komentatorów, przekonując wszystkich wokół, że upowszechniają wynalazki, które przyniosą korzyści całej ludzkości.
Głosów krytycznych jest zdecydowanie mniej i są słabiej słyszalne. Mam sporo obaw, że rysowana przez solucjonistów technologicznych utopia, o którą nikt ich de facto nie prosił, może okazać się dystopią – światem pełnym dezinformacji, cenzury, jeszcze większej asymetrii i centralizacji władzy. Światem, jeszcze częściej i mocniej od tego dzisiejszego, odzierającym ludzi z godności i odbierającym poczucie sensu.
Zdecydowałem, że podejmę próbę opisania tematu, wskazując swoje obawy. Wiem, że jednym tekstem nie wyczerpię tak szerokiego zagadnienia. Aby utrzymać sens i głębię swojej argumentacji, musiałbym napisać albo bardzo długi artykuł, który ciężko byłoby przeczytać za jednym zamachem, albo użyć pojęć i skrótów, które może znacząco skróciłyby tekst, ale utrudniłyby jego zrozumienie. A mnie o rozumienie właśnie chodzi. Dlatego też przygotowuję serię artykułów, które będę sukcesywnie publikować. I choć z pewnością tematu i tak nie wyczerpię, to wierzę, że zaproszę Ciebie droga czytelniczko oraz Ciebie drogi czytelniku, do refleksji i rozmowy na temat świata, który wyłania się na naszych oczach. Być może razem coś będziemy mogli zaradzić?
Pierwszy tekst z serii „Zalecam ostrożność” poświęcę czatowi GPT i wrażeniu spójności.
Stochastyczna papuga

Zwierzęta mają swoje szczególne miejsce w słowniku biznesowych i naukowych metafor. W ostatnich latach dominowały (paradoksalnie) rzadko spotykane czarne łabędzie, słonie w pokojach, o których nikt nie chciał rozmawiać i szare nosorożce. W tym niezwykłym zwierzyńcu znalazło się ostatnio miejsce dla papugi.
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major i Shmargaret Shmitchell w swoim artykule „On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” wprowadziły to urocze zwierzę, aby pokazać, że duże modele językowe (Large Language Models), o których dzięki czatowi GPT zrobiło się ostatnio bardzo głośno, przypominają papużki, które powtarzają to, co kiedyś usłyszały. Mimo, że nie są to kosmici, którzy przylecieli zniszczyć Ziemian, to nie dajmy się zwieść! Takie urocze papużki mogą narobić sporo bałaganu.
Zacznę jednak od wyjaśnienia działania stochastycznej papugi. Prześlizgnę się po temacie i będę korzystać z uproszczeń, które przedstawią ogólną zasadę, bez wchodzenia w szczegóły. Temat jest opisywany przez wielu specjalistów. Wszystkich zainteresowanych modelami językowymi odsyłam do bardzo wciągającego podręcznika „Speech and Language Processing” autorstwa Daniela Jurafsky’ego (Stanford University) i Jamesa H. Martina (University of Colorado at Boulder), a o szczegółach budowy GPT-3 można przeczytać chociażby na stronie OpenAI czy w Wikipedii.
Model językowy (Language Model) na potrzeby tego tekstu zdefiniuję jako program komputerowy, który wykorzystuje uczenie maszynowe (Machine Learning). Model taki nie jest zaprogramowany w sposób tradycyjny, tylko jest trenowany na zbiorach danych testowych do wykrywania wzorców i korelacji, aby nauczyć się przewidywać prawdopodobieństwo wystąpienia kolejnego wyrazu w sekwencji (np. w rozpoczętym zdaniu). Metodą prób i błędów model stara się uzupełnić tekst, aby zmaksymalizować prawdopodobieństwo uzyskania oczekiwanego przez odbiorcę wyniku, biorąc przy tym pod uwagę informacje, które uzyskał na wejściu. Tak wytrenowany model może potem służyć do generowania dobrze brzmiących odpowiedzi na zadane w języku naturalnym pytania.
Przykład: Wprowadzamy w interfejsie tekstowym modelu językowego sekwencję „Wszystkie koty piją...” prosząc o dokończenie zdania. Największe prawdopodobieństwo kolejnego wyrazu model przypisze do słowa „mleko” (mimo, że nie jest to prawda nt. kotów). Wynika to z faktu, że w wielu tekstach w naszej kulturze przyjęło się często korzystać z tego stwierdzenia, a model był trenowany właśnie na tekstach, które powielały taką informację. Podczas trenowania najwięcej razy prawidłową odpowiedzią było „mleko”, dlatego w wyniku reprezentacji statystycznej w zbiorze danych treningowych, model „uzna”, że najwyższe prawdopodobieństwo oczekiwanej odpowiedzi dla czytelnika będzie miało słowo „mleko”, w przeciwieństwo do „wodę”, „colę”, czy „herbatę”.
Jaki powinien być kolejny wyraz w tym zdaniu? Być może najwyższe prawdopodobieństwo model przypisze do spójnika „i”, a następnie do „dużo”, oraz „śpią”, w rezultacie generując zakończenie „... mleko i dużo śpią”.
W zależności od architektury modelu, wielkości zbioru danych treningowych, sposobu trenowania, model językowy lepiej lub gorzej radzi sobie z przewidywaniem, jakie słowa i zdania generować, w odpowiedzi na kontekst wynikający z pytania (tzw. promptu), które otrzymał na wejściu, tak aby brzmieć jak najbardziej spójnie dla odbiorcy. ChatGPT jest w tym szczególnie dobry, bowiem jest już wytrenowany, więc najczęściej „wie” co odpowiedzieć – jego początkowy zbiór danych treningowych był olbrzymi (500 miliardów tokenów tekstowych), a z racji swojej architektury nie tylko „rozumie” znaczenie słów, ale także ich kolejność i skutecznie antycypuje również kontekst słów, aby wydobyć znaczenia, które przypisał do nich w danej chwili człowiek.
Wrażenie spójności
Każdy, kto korzystał z ChatGPT mógł odnieść wrażenie, że nie rozmawia z programem komputerowym, tylko z bytem, który samodzielnie myśli. Nieraz błyskotliwe, czasem nieporadne i zabawne odpowiedzi czatu mogą wielu zachwycać, pokazując nową jakość w interakcji człowieka z maszyną. Problem w tym, że odpowiedzi czatu są tylko spójne na pozór.
Spójność (koherencja) w lingwistyce posiada kilka definicji. Jedna z najpopularniejszych, to zaproponowana przez Roberta De Beaugrande’a i Wolfganga U. Dresslera, mówiąca że spójność to”kontynuacja sensów” (continuity of senses). Idąc za tym, można powiedzieć, że jest to zdolność rozpoznawania przekonań i intencji rozmówców w określonym kontekście. Innymi słowy między jednostkami jest chęć komunikacji i coś co łączy (łączyć może też różnica poglądów) i sprawia, że zachodzi komunikacja. Język jest nośnikiem w komunikacji i wpływa na to jak myślimy, czujemy, nadajemy sens światu.
Emily M. Bender z zespołem w swoim artykule opisały tę kwestię w następujący sposób:
[...]jako taka, komunikacja międzyludzka opiera się na interpretacji ukrytego znaczenia przekazywanego między jednostkami. Fakt, że komunikacja międzyludzka jest wspólnie konstruowaną czynnością, jest najwyraźniej prawdziwy w przypadku komunikacji mówionej lub migowej, ale używamy tych samych możliwości do tworzenia języka, który jest przeznaczony dla odbiorców, którzy nie są z nami współobecni (czytelnicy, słuchacze, obserwatorzy na odległość w czasie lub przestrzeni) oraz w interpretacji takiego języka, kiedy się z nim spotykamy. Musi z tego wynikać, że nawet jeśli nie znamy osoby, która wygenerowała język, który interpretujemy, budujemy częściowy model tego, kim ona jest i jaką wspólną płaszczyznę ma z nami, i wykorzystujemy to do interpretacji jej słów.
W tekście wygenerowanym przez program komputerowy, taki jak np. ChatGPT nie ma zakorzenienia w intencji komunikacyjnej czy w jakimś spójnym obrazie rzeczywistości. Jest to sprytnie działający, wytrenowany model językowy. Wrażenie spójności, którego doświadcza odbiorca wynika z tego, że „nasze (ludzkie) postrzeganie tekstu w języku naturalnym, niezależnie od tego, jak został wygenerowany, jest zapośredniczone przez nasze własne kompetencje językowe i nasze predyspozycje do tego, aby interpretować akty komunikacyjne jako przekazujące spójne znaczenie i intencję, niezależnie od tego, czy takie mają, czy nie.” – podsumowuje Emiliy M. Bender z zespołem.
Wynika z tego, że spójność wypowiedzi ChatGPT jest pozorna, bowiem widoczna jest tylko w oczach odbiorcy (czytelnika), a po drugiej stronie jest bezosobowy program (za którym stoi jednak wielka korporacja i jej interesy). Z jednej strony jest człowiek, który nadaje sens i znaczenie tekstowi, który czyta, a z drugiej strony jest sekwencja nic nie znaczących dla programu słów i form językowych, które wybrał ze swojego olbrzymiego zbioru danych treningowych, zgodnie z informacjami o tym jak je łączyć, korzystając z reguł prawdopodobieństwa.
Czy to nadal jest rozmowa?
„Trochę jakby” rozmowa ze stochastyczną papugą
Daniel Kahneman, psycholog i laureat Nagrody Nobla w dziedzinie ekonomii w swojej książce „Pułapki Myślenia” spopularyzował koncepcję wprowadzoną przez psychologów Keitha Stanovicha i Richarda Westa znaną jako myślenie szybkie i wolne (lub system 1. i systemem 2.) System pierwszy podejmuje decyzje szybko, intuicyjnie, w oparciu o wyuczone wzorce, często popełniając błędy. System drugi natomiast jest powolny, świadomy, logiczny, a jego użycie wymaga od nas zdecydowanie więcej wysiłku, niż gdy oprzemy się o tzw. intuicję.
Często zawierzam swojej intuicji, zamiast coś przeanalizować na chłodno. Idę za tym, co w danej chwili uważam za właściwe. Jednak gdy zastanawiam się post factum, dlaczego zachowałem się w dany sposób, to tylko czasami znajduję jakieś logiczne uzasadnienie, które raczej jest błędne, niezależnie czy jestem zadowolony z rezultatu. Zadziałał bowiem system 1, a to jak zinterpretuje to system 2, nie zbliża mnie do prawdy.
Z metaforą myślenia szybkiego i wolnego coraz częściej spotykam się w wykładach dotyczących sztucznej inteligencji (np. w tym świetnym wykładzie z SAIConference, czy w wykładzie Dana Lametii), gdzie to właśnie szybkie myślenie, a nie myślenie algorytmiczne, przypisywane jest do zasad działania AI, w tym do modeli językowych takich jak ChatGPT.
Wiążą się z tym m.in. następujące problemy:
- model jest tak dobry, jak dane treningowe, które otrzymał (co prowadzi do wielu nadużyć i wykluczeń),
- człowiek nie jest w stanie zrozumieć, w jaki sposób model językowy uzyskał daną odpowiedź (z perspektywy człowieka sposób dochodzenia do odpowiedzi jest tak złożony, że nie ma możliwości przejścia przez ścieżkę decyzyjną, co implikuje olbrzymie problemy, o których napiszę w kolejnych artykułach),
- model nie „rozumie”, tylko „obstawia” najbardziej oczekiwany wynik,
- model może podawać błędne odpowiedzi, i nie ma o tym pojęcia (co generuje kolejne problemy).
Wszystkie powyższe problemy oraz wiele kolejnych szczegółowo omówię w kolejnych tekstach.
Zalecam ostrożność
W artykule starałem się wykazać, że nie mamy do czynienia z rozmową rozumianą w kategoriach ludzkich, której uczestnicy mają coś ze sobą wspólnego, tylko bardziej ze „zgadywanką” – próbą znalezienia przez model językowy odpowiedzi, która jest najbliższa oczekiwanej. Pozorna spójność wypowiedzi modelu językowego, której doświadcza odbiorca poprzez naturalną dla ludzi skłonność do interpretacji aktów komunikacji jako czegoś co ma intencję i znacznie, wzmacnia problem. Efektem tego może być zbudowane u odbiorcy przekonanie nt. prawdziwości otrzymanego rezultatu, jak i prawdziwości samej rozmowy. W szczególności, kiedy odbiorca nie chce lub nie potrafi samodzielnie zweryfikować, czy odpowiedź jest sensowna, oparta na faktach, rzetelnych źródłach, wolna od uprzedzeń.
Przykładami takich „zgadywanek”, które mają błędne wyniki są np. działania matematyczne. Modele językowe nie potrafią liczyć, ponieważ są trenowane do uzupełniania tekstów, więc podają odpowiedź, która jest zbliżona do najbardziej oczekiwanej (działania matematyczne, to wszak myślenie wolne, a nie szybkie).

Prawidłowa odpowiedź to 27 287 158.
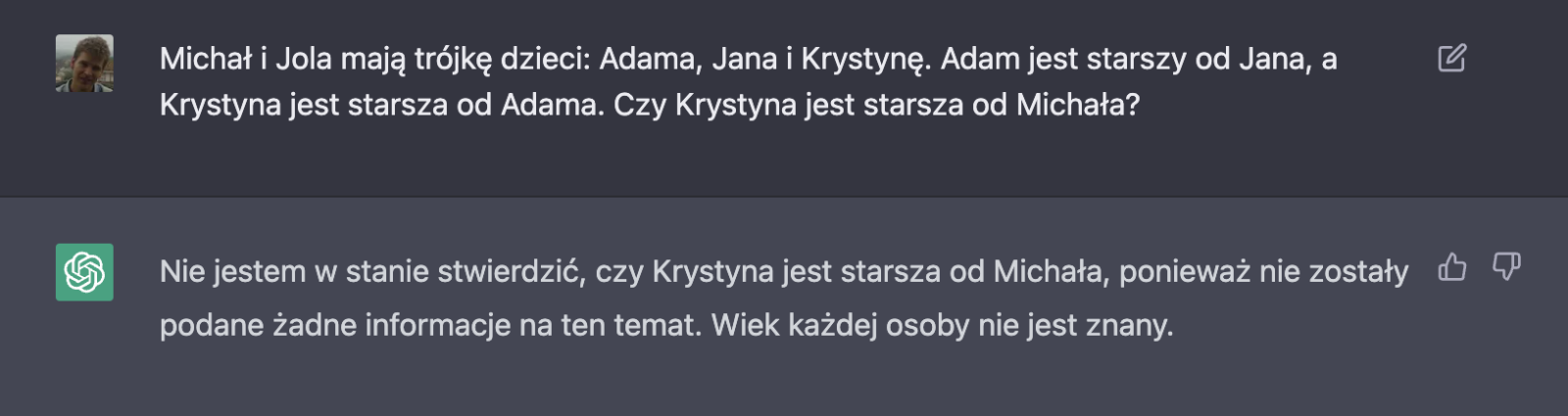
Innym przykładem są pytania, w których, konieczne jest rozumie złożonych konceptów w danej kulturze np. tego jak funkcjonuje rodzina.
Nie chcę w tej chwili rozwijać wątku błędnych odpowiedzi generowanych przez ChatGPT. Internet jest pełny zrzutów ekranu z konwersacji z czatem, które głównie funkcjonują jako zabawne żarty lub przestroga.
W tym wpisie dotknąłem dopiero wierzchołka góry lodowej, wyjaśniając logikę działania modelu językowego i problem z interpretacją spójności wypowiedzi, zahaczając o pojęcia faktu oraz prawdy.
Pospieszę się z kolejnym artykułem, bowiem za moment moje teksty utoną w morzu stron i artykułów wygenerowanych przez modele językowe (wcześniej je dokarmiając), które będą łudząco podobne, do tych pisanych przez ludzi. Będą jednak syntetycznym wytworem pozbawionym duszy, którym ludzka wrażliwość tę duszę będzie dorabiać, wierząc, że po drugiej stronie była intencja i znaczenie.
Po drugiej stronie będzie jednak maszyna, z każdym dniem doskonalej operująca słowem, imitująca style, plagiatująca treści innych autorów, wymyślająca „fakty”, pisząca bez namysłu wszystko co zechce „zlecający”, niezależnie czy będzie tworzyć wartościowy tekst naukowy, czy szerzyć dezinformację, odbierając przy tym ludziom zapał i chęć do samodzielnego pisania i twórczego wyrażania się. Z resztą, co ja piszę... to już się dzieje, tylko wykładniczo wzrośnie skala.
A może są inne możliwe przyszłości?
Na koniec bonus dla wytrwałych. Widząc zalew niezwykle słabych merytorycznie treści na dany temat, o dużej popularności i jednocześnie odnajdując w sieci niezwykle wartościowe treści, które były niepopularne, postanowiłem przetestować ChatGPT.